Python, Docker e dipendenze “pesanti”
/ 3 min read
Updated:Table of Contents
Python, Docker e dipendenze “pesanti”
Come sfida personale mi sono posto l’obbiettivo di ottimizzare il peso di alcune immagini Docker che giornalmente mi trovo a rilasciare.
Giorno dopo giorno notavo che i tempi di build e rilascio continuavano a crescere, passando dai 5 minuti di media a piu di 20 in alcuni casi.
Rispetto alle altre immagini solite queste hanno diverse dipendenze Python che includono pytorch, tensorflow e varie altre librerie legate al mondo AI.
Caso Studio
Ho creato un progetto molto semplice dove potevo studiare e giocare con le dipendenze di torch.
Nel progetto originale in cui si è verificata questa anomalia c’erano molte piu dipendenze che venivano installate e quindi alcuni passaggi che qui sembrano scontati non lo sono stati nel momento un cui cercavo di capire chi potesse essere la causa.
Il progetto è disponibile su Github.
Nel progetto si trovano anche due Dockerfile per buildare le immagini correttamente per la versione cpu e la versione gpu.
Nella cartella dev è presente uno script che crea i due virtualenv allo stesso tempo.
Una volta avviato, utilizzando ncdu si ha subito la conferma della differenza di peso dei due virtualenv.
Attivando prima uno e poi l’altro virtualenv e lanciando il comando torch-exp si può verificare che la creazione e l’uso del modello funzionano in entrambi gli ambienti.
A livello di codice non è niente di interessante. E’ l’esempio classico di MNIST che si trova sulla documentazione di torch.
Il mio interesse era solo che si addestrasse un modello e si potesse valutare. Non era interessante cosa facesse.
Prova sul campo
Creo il virtualenv e installo torch
uv venv source .venv/bin/activate uv pip install torch uv pip install torchvisionNoto che la lista delle dipendenze è molto lunga e ci mette molto tempo ad installare il tutto.
Mentre guardo il terminale fare il suo lavoro intravedo le sottostringhe nvidia e cuda.
Questo mi accende la prima lampadina perchè nell’utilizzo giornaliero per eseguire l’inferenza sul modello non sfrutto la GPU ma solo la CPU.
Ed è qui che mi viene un sospetto e lancio ncdu sulla root del progetto.
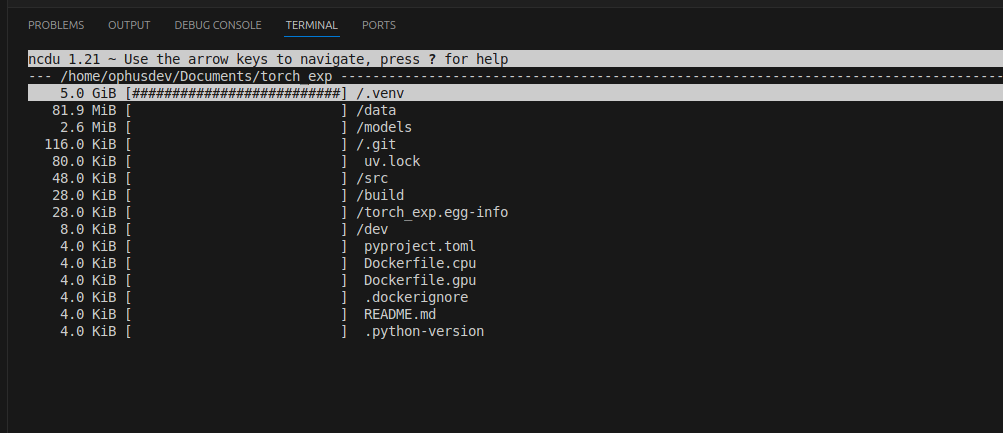
Noto subito che la cartella del virtualenv è di dimensioni esagerate.
Attivo la mia modalità investigazione e installo uv pip install pipdeptree e con il comando pipdeptree -fl cerco quale libreria richiede l’uso delle cuda e noto che è legato a torch.
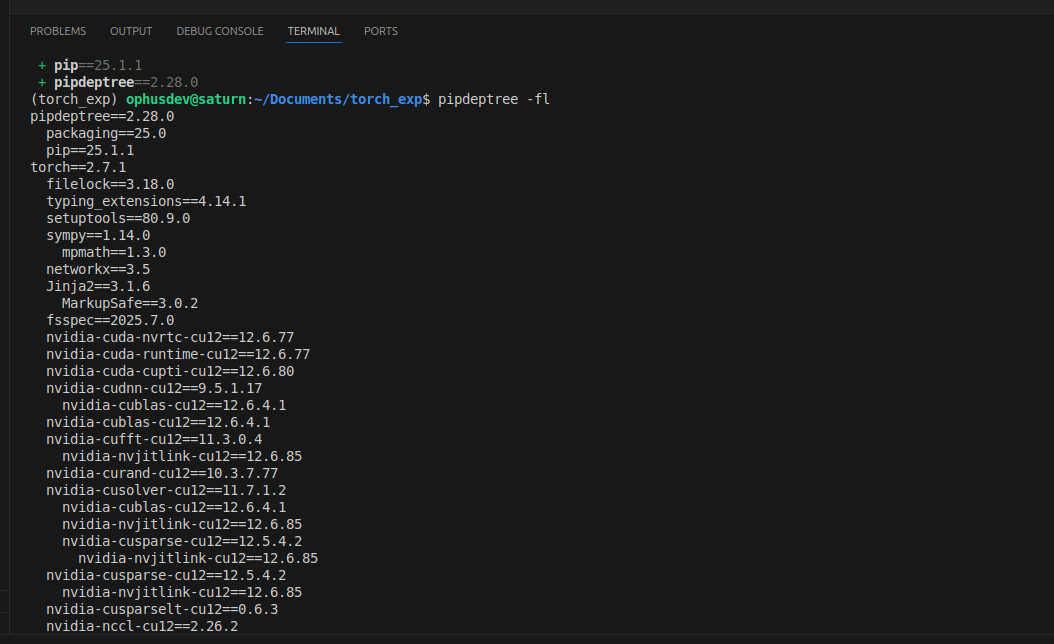
Spulcio la documentazione di torch e trovo che esiste anche la possibilità di sfruttarlo via CPU https://pytorch.org/get-started/locally/.
Ottimo, allora setto questa possibilità nel mio pyproject.toml valorizzando le sezioni:
- [project.optional-dependencies]
- [tool.uv]
- [tool.uv.sources]
- [[tool.uv.index]]
Mi concentro sulla sezione [[tool.uv.index]] che riferisce a pytorch-cpu e vado ad inserire l’url dell’index che punta ai pacchetti riferiti alla cpu.
Cancello il venv e lo ricreo utilizzando l’installazione delle dipendenze che riguardano la cpu
deactivaterm -rf .venvuv venvsource .venv/bin/activateuv sync --extra cpuVado di nuovo di ncdu e siamo drasticamente scesi con il peso del nostro virtualenv.
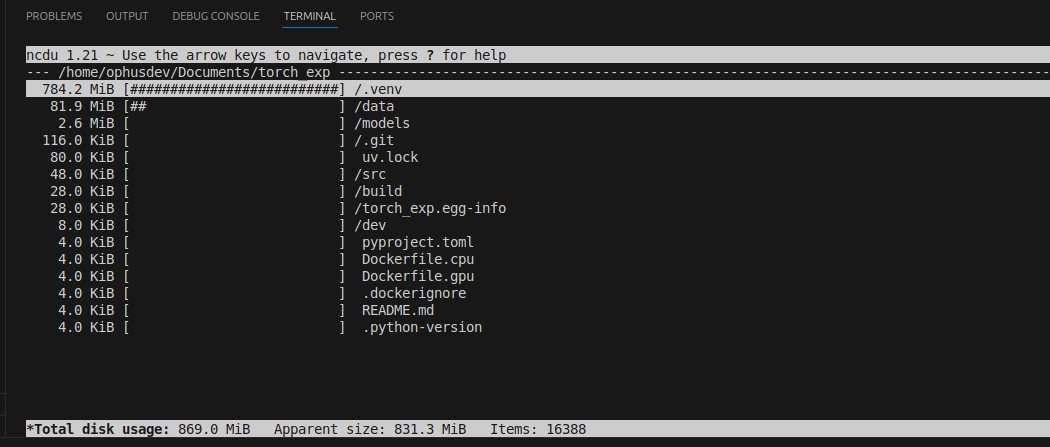
Installazione GPU
Nel caso in cui per necessità di sviluppo o di utilizzo dell’inferenza su GPU basta installare le dipendenze per la GPU usando
uv venvsource .venv/bin/activateuv sync --extra gpuNote Extra
Prima di configurare il pyproject.toml ho fatto qualche esperimento con un file requirements.txt e c’è la possibilità anche nell’installazione via requirements file di impostare un url di index “custom”
--extra-index-url https://download.pytorch.org/whl/cputorch==2.7.1torchvision==0.22.1In questo modo verranno installati i pacchetti che sfruttano la cpu.